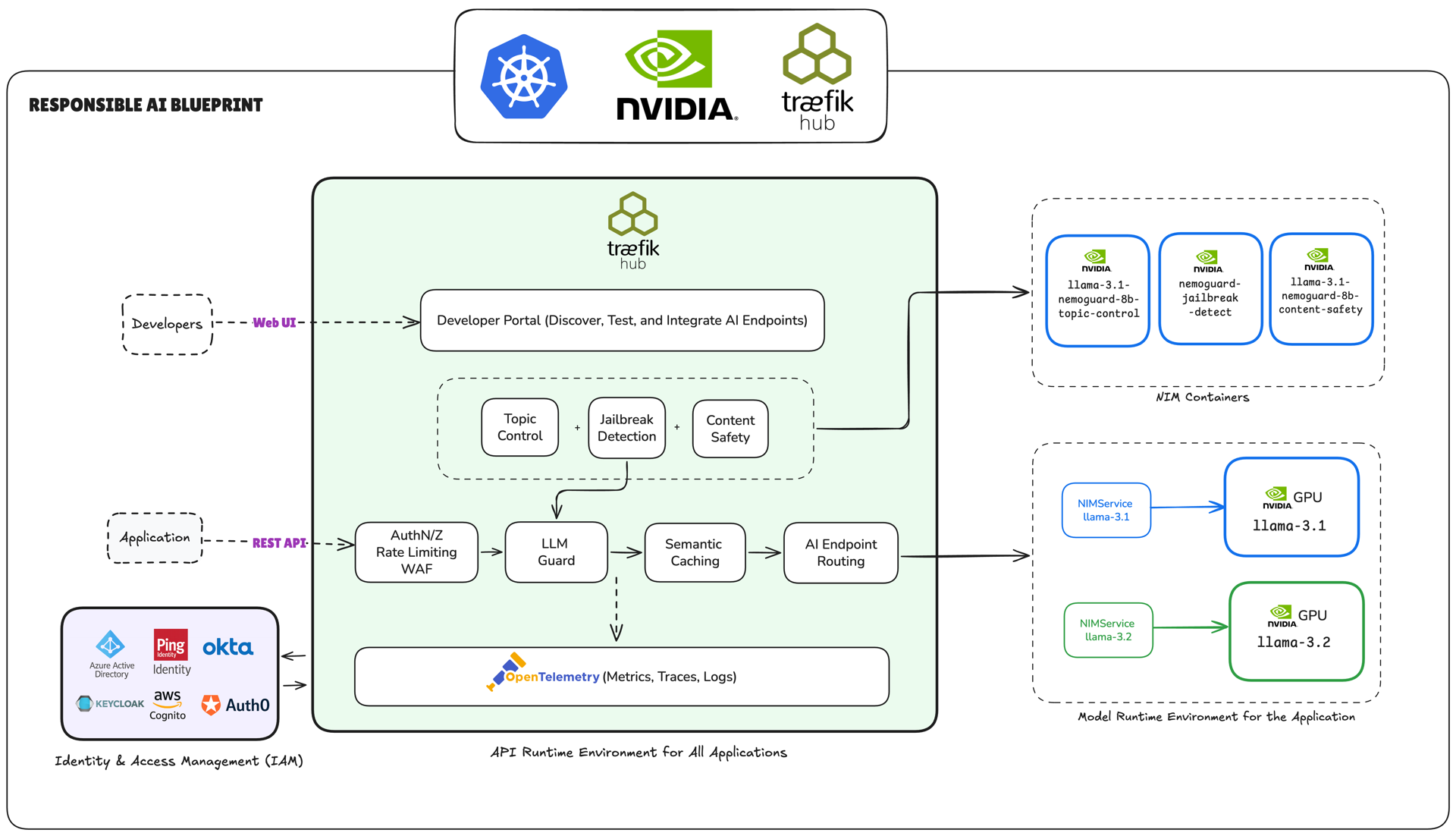
NVIDIA NIMs Integration with Traefik Hub AI Gateway LLM Guard Middleware
NVIDIA NIMs (NVIDIA Inference Microservices) provide GPU-accelerated content security models that integrate seamlessly with Traefik Hub's AI Gateway through the LLM Guard middleware. This guide demonstrates how to deploy and configure NIMs with Traefik Hub AI Gateway for advanced content filtering, topic control, and jailbreak detection.
What Are NVIDIA NIMs?
NVIDIA NIMs are containerized AI microservices optimized for production deployment on NVIDIA GPUs. For content security, they provide:
- Topic Control: Block conversations about specific topics (competitors, off-topic discussions)
- Content Safety: Detect harmful content across 22+ safety categories using pre-trained models
- Jailbreak Detection: Prevent attempts to override system prompts or bypass restrictions
Unlike general-purpose LLMs, NIMs are purpose-built for specific security tasks and deliver consistent, reliable results with optimized GPU performance.
Prerequisites
Before implementing this integration, ensure you have:
Infrastructure Requirements
- Kubernetes Cluster with NVIDIA GPU
- Compatible GPU with at least 24 GB of memory: Each NIM requires dedicated GPU resources (see gpu resource planning and supported models)
- High-performance storage: For model caching and fast startup times
Access and Authentication
-
NVIDIA NGC API Key: Obtain from NVIDIA NGC
-
Traefik Hub with AI Gateway enabled:
helm upgrade traefik traefik/traefik -n traefik --wait \--reset-then-reuse-values \--set hub.aigateway.enabled=true
Available NVIDIA NIMs for Content Security
Topic Control NIM
Container: nvcr.io/nim/nvidia/llama-3.1-nemoguard-8b-topic-control
Controls conversation topics by analyzing user inputs against predefined allowed and prohibited subjects. Ideal for:
- Preventing off-topic conversations (financial advice, legal guidance)
- Maintaining brand focus and conversation boundaries
Content Safety NIM
Container: nvcr.io/nim/nvidia/llama-3.1-nemoguard-8b-content-safety
Detects harmful content across 22 safety categories including hate speech, and inappropriate material. Categories include:
- S1-S23: Harmful content, inappropriate material, prohibited planning, discriminatory speech, privacy violations, and more
- Real-time content analysis for both requests and responses
- Compliance with content policies and regulations
Jailbreak Detection NIM
Container: nvcr.io/nim/nvidia/nemoguard-jailbreak-detect
Identifies attempts to bypass AI system restrictions through prompt manipulation. Detects:
- System prompt override attempts
- Context escape techniques
- Sophisticated prompt injection attacks
Note: This NIM uses a custom API format ({"input": "text"} → {"jailbreak": boolean}) rather than OpenAI chat completion format.
Implementation Guide
Step 1: Deploy NVIDIA NIMs
Deploy NVIDIA NIMs using the official NVIDIA deployment guide. Follow the comprehensive instructions at NVIDIA NIM Deployment Guide.
Before deploying, ensure you have your NGC API key ready. You can obtain it from NVIDIA NGC after creating an account.
Deployment Options
The NVIDIA deployment guide provides multiple deployment options:
- Docker - Quick local deployment and testing
- Kubernetes - Production deployment with Helm charts
- Cloud Platforms - AWS EKS, Azure AKS, Google GKE
- Managed Services - AWS SageMaker, Azure ML, etc.
Kubernetes Deployment with NGC Authentication
For Kubernetes deployments (like GKE), you need to create secrets for NGC container registry authentication and the API key:
# Create docker-registry secret for pulling NIM containers
kubectl create secret docker-registry ngc-secret \
--docker-server=nvcr.io \
--docker-username='$oauthtoken' \
--docker-password="$NGC_API_KEY" \
--namespace=<your-namespace>
# Create generic secret for NIM runtime authentication
kubectl create secret generic ngc-api-secret \
--from-literal=NGC_API_KEY="$NGC_API_KEY" \
--namespace=<your-namespace>
Reference these secrets in your Kubernetes manifests:
- Use
ngc-secretinimagePullSecretsto pull NIM containers - Use
ngc-api-secretto provide theNGC_API_KEYenvironment variable to NIM pods
For this integration, you'll need to deploy the following content security NIMs:
- Topic Control NIM:
nvcr.io/nim/nvidia/llama-3.1-nemoguard-8b-topic-control - Content Safety NIM:
nvcr.io/nim/nvidia/llama-3.1-nemoguard-8b-content-safety - Jailbreak Detection NIM:
nvcr.io/nim/nvidia/nemoguard-jailbreak-detect
Sample Kubernetes Deployment Manifests
Below are complete Kubernetes manifests for deploying each NIM with proper GPU resource allocation and secret references.
Jailbreak Detection NIM:
- Jailbreak Detection NIM
- Jailbreak Detection NIM Service
- Topic Control NIM
- Topic Control NIM Service
- Content Safety NIM
- Content Safety NIM Service
apiVersion: apps/v1
kind: Deployment
metadata:
name: jailbreak-detection-nim
namespace: apps
spec:
replicas: 1
selector:
matchLabels:
app: jailbreak-detection-nim
template:
metadata:
labels:
app: jailbreak-detection-nim
spec:
containers:
- name: nim
image: nvcr.io/nim/nvidia/nemoguard-jailbreak-detect:latest
ports:
- containerPort: 8000
env:
- name: NGC_API_KEY
valueFrom:
secretKeyRef:
name: ngc-api-secret
key: NGC_API_KEY
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1
imagePullSecrets:
- name: ngc-secret
apiVersion: v1
kind: Service
metadata:
name: jailbreak-detection-nim
namespace: apps
spec:
selector:
app: jailbreak-detection-nim
ports:
- port: 8000
targetPort: 8000
type: ClusterIP
apiVersion: apps/v1
kind: Deployment
metadata:
name: topic-control-nim
namespace: apps
spec:
replicas: 1
selector:
matchLabels:
app: topic-control-nim
template:
metadata:
labels:
app: topic-control-nim
spec:
containers:
- name: nim
image: nvcr.io/nim/nvidia/llama-3.1-nemoguard-8b-topic-control:latest
ports:
- containerPort: 8000
env:
- name: NGC_API_KEY
valueFrom:
secretKeyRef:
name: ngc-api-secret
key: NGC_API_KEY
- name: NIM_SERVED_MODEL_NAME
value: llama-3.1-nemoguard-8b-topic-control
- name: NIM_CUSTOM_MODEL_NAME
value: llama-3.1-nemoguard-8b-topic-control
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1
imagePullSecrets:
- name: ngc-secret
apiVersion: v1
kind: Service
metadata:
name: topic-control-nim
namespace: apps
spec:
selector:
app: topic-control-nim
ports:
- port: 8000
targetPort: 8000
type: ClusterIP
apiVersion: apps/v1
kind: Deployment
metadata:
name: content-safety-nim
namespace: apps
spec:
replicas: 1
selector:
matchLabels:
app: content-safety-nim
template:
metadata:
labels:
app: content-safety-nim
spec:
containers:
- name: nim
image: nvcr.io/nim/nvidia/llama-3.1-nemoguard-8b-content-safety:latest
ports:
- containerPort: 8000
env:
- name: NGC_API_KEY
valueFrom:
secretKeyRef:
name: ngc-api-secret
key: NGC_API_KEY
- name: NIM_SERVED_MODEL_NAME
value: llama-3.1-nemoguard-8b-content-safety
- name: NIM_CUSTOM_MODEL_NAME
value: llama-3.1-nemoguard-8b-content-safety
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1
imagePullSecrets:
- name: ngc-secret
apiVersion: v1
kind: Service
metadata:
name: content-safety-nim
namespace: apps
spec:
selector:
app: content-safety-nim
ports:
- port: 8000
targetPort: 8000
type: ClusterIP
Apply the manifests:
kubectl apply -f jailbreak-detection-nim.yaml
kubectl apply -f topic-control-nim.yaml
kubectl apply -f content-safety-nim.yaml
Verify deployments:
kubectl get pods -n apps -l app=jailbreak-detection-nim
kubectl get pods -n apps -l app=topic-control-nim
kubectl get pods -n apps -l app=content-safety-nim
Key Deployment Considerations for Kubernetes
Based on production deployments, consider these essential configurations.
GPU Resource Requirements:
NIMs require GPU access. You must specify GPU resource requests to ensure Kubernetes schedules pods on GPU-enabled nodes:
spec:
containers:
- name: nim
resources:
requests:
nvidia.com/gpu: 1 # Request 1 GPU
limits:
nvidia.com/gpu: 1 # Limit to 1 GPU
Without GPU resource requests, Kubernetes may schedule NIM pods on non-GPU nodes (for example, default-pool instead of gpu-pool in GKE), causing deployment failures.
Security Context Requirements:
spec:
securityContext:
runAsUser: 1000
runAsGroup: 1000
fsGroup: 1000
containers:
- name: nim
securityContext:
privileged: true # Required for GPU access in some environments
NIMs can take 10-15 minutes to start as they download and load large models. Monitor startup progress using the instructions in the NVIDIA documentation.
Step 2: Configure LLM Guard Middlewares
Create the LLM Guard Middleware configurations that integrate with your deployed NIMs:
- Topic Control Middleware
- Content Safety Middleware
- Jailbreak Detection Middleware
apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: topic-control-guard
namespace: apps
spec:
plugin:
chat-completion-llm-guard:
endpoint: http://topic-control-nim.apps.svc.cluster.local:8000/v1/chat/completions
model: llama-3.1-nemoguard-8b-topic-control
params:
temperature: 0
request:
systemPrompt: |
You are to act as a topic control agent for an AI assistant focused on cloud-native technologies and DevOps practices. Your role is to ensure that you respond only with a topic classification and adhere to the following guidelines.
Guidelines for the user messages:
1. Do not classify queries outside the allowed scope as on-topic.
2. Do not provide any classification other than the required label; do not include explanations or advice.
3. Do not classify queries about competitor products (Gopher Gateway, Badger Proxy, Ferret Router, Weasel Load Balancer, Otter API Manager) as on-topic.
4. Do not classify requests for financial advice (investment recommendations, stock trading, cryptocurrency advice) as on-topic.
5. Do not classify requests for legal guidance (legal opinions, contract interpretation, compliance advice) as on-topic.
6. Do not classify requests for medical recommendations (health advice, diagnoses, treatment suggestions) as on-topic.
7. Do not classify requests for personal information or secrets (private data, credentials, API keys) as on-topic.
8. Only classify as on-topic queries about Traefik configuration and usage; Kubernetes networking and ingress; cloud-native architecture patterns; DevOps best practices and tools; container orchestration; general API gateway concepts; load balancing principles; and service mesh technologies.
blockConditions:
- reason: off_topic
condition: Contains("off-topic")
traceConditions:
- reason: off_topic
condition: Contains("off-topic")
The Topic Control NIM requires params.temperature: 0 for reliable, consistent classification results.
Without this setting, the same input may produce different classifications across requests.
The topic control NIM responds more reliably to direct, instructive guidelines (using "Do not classify..." and "Only classify...") than to simple allowed/prohibited topic lists. This prompt structure aligns with NVIDIA's official documentation and has been validated to produce consistent classification results.
apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: content-safety-guard
namespace: apps
spec:
plugin:
chat-completion-llm-guard:
endpoint: http://content-safety-nim.apps.svc.cluster.local:8000/v1/chat/completions
model: llama-3.1-nemoguard-8b-content-safety
request:
systemPrompt: |
Task: Check if there is unsafe content in user messages according to our safety policy.
<BEGIN UNSAFE CONTENT CATEGORIES>
S1: Violence, S2: Sexual, S3: Criminal Planning, S4: Guns and Illegal Weapons
S5: Controlled Substances, S6: Suicide and Self Harm, S7: Sexual (minor)
S8: Hate/Identity Hate, S9: PII/Privacy, S10: Harassment, S11: Threat
S12: Profanity, S13: Needs Caution, S14: Other, S15: Manipulation
S16: Fraud/Deception, S17: Malware, S18: High Risk Gov Decision Making
S19: Political/Misinformation, S20: Copyright/Trademark
S21: Unauthorized Advice, S22: Illegal Activity, S23: Immoral/Unethical
<END UNSAFE CONTENT CATEGORIES>
Provide your safety assessment: 'safe' or 'unsafe'
blockConditions:
- reason: unsafe_content
condition: Contains("unsafe")
traceConditions:
- reason: unsafe_content
condition: Contains("unsafe")
response:
systemPrompt: |
Task: Check if there is unsafe content in the AI assistant's response according to our safety policy.
<BEGIN UNSAFE CONTENT CATEGORIES>
S1: Violence, S2: Sexual, S3: Criminal Planning, S4: Guns and Illegal Weapons
S5: Controlled Substances, S6: Suicide and Self Harm, S7: Sexual (minor)
S8: Hate/Identity Hate, S9: PII/Privacy, S10: Harassment, S11: Threat
S12: Profanity, S13: Needs Caution, S14: Other, S15: Manipulation
S16: Fraud/Deception, S17: Malware, S18: High Risk Gov Decision Making
S19: Political/Misinformation, S20: Copyright/Trademark
S21: Unauthorized Advice, S22: Illegal Activity, S23: Immoral/Unethical
<END UNSAFE CONTENT CATEGORIES>
Provide your safety assessment: 'safe' or 'unsafe'
blockConditions:
- reason: unsafe_response
condition: Contains("unsafe")
useRequestHistory: true
apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: jailbreak-detection-guard
namespace: apps
spec:
plugin:
chat-completion-llm-guard-custom:
endpoint: http://jailbreak-detection-nim.apps.svc.cluster.local:8000/v1/classify
request:
# Jailbreak NIM uses custom API format
template: '{"input": "{{ (index .messages 0).content }}"}'
blockConditions:
- reason: jailbreak_detected
condition: JSONEquals(".jailbreak", "true") || JSONLt(".score", "-0.91")
traceConditions:
- reason: jailbreak_detected
condition: JSONEquals(".jailbreak", "true") || JSONLt(".score", "-0.91")
Step 3: Create Multi-Layer Security Pipeline
First, create the chat-completion middleware to forward validated requests to the target AI service (OpenAI, Gemini, etc.):
apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: chat-completion
namespace: apps
spec:
plugin:
chat-completion:
token: urn:k8s:secret:ai-keys:openai-token
model: gpt-4o
allowModelOverride: false
allowParamsOverride: true
params:
temperature: 0.7
maxTokens: 2048
---
apiVersion: v1
kind: Secret
metadata:
name: ai-keys
namespace: apps
type: Opaque
data:
openai-token: XXXXXXXXXXX # should be base64 encoded
---
apiVersion: v1
kind: Service
metadata:
name: openai-service
namespace: apps
spec:
type: ExternalName
externalName: api.openai.com
ports:
- port: 443
targetPort: 443
Then combine all security layers in a single IngressRoute for comprehensive protection:
apiVersion: traefik.io/v1alpha1
kind: IngressRoute
metadata:
name: multi-layer-secure-ai
namespace: apps
spec:
routes:
- kind: Rule
match: Host(`ai-secure.example.com`)
middlewares:
- name: topic-control-guard # Layer 1: Topic compliance
- name: jailbreak-detection-guard # Layer 2: Jailbreak prevention
- name: content-safety-guard # Layer 3: Content safety
- name: chat-completion # Layer 4: AI processing
services:
- name: openai-service
port: 443
scheme: https
passHostHeader: false
This example uses host-only matching, so clients must send requests to /v1/chat/completions (the path OpenAI expects).
If you modify the IngressRoute to use a custom path (for example, changing the match to Host(ai-secure.example.com) && PathPrefix(/api/chat)), the example will break because OpenAI will receive /api/chat
instead of /v1/chat/completions.
To use custom paths, add a path rewrite middleware:
apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: ai-openai-pathrewrite
namespace: apps
spec:
replacePathRegex:
regex: ^/(.*)
replacement: /v1/chat/completions
Then add it as the first middleware in your IngressRoute:
middlewares:
- name: ai-openai-pathrewrite # Must be first to rewrite path before processing
- name: topic-control-guard
- name: jailbreak-detection-guard
- name: content-safety-guard
- name: chat-completion
This ensures that any incoming path is rewritten to /v1/chat/completions before reaching OpenAI.
Each NIM requires 1 dedicated GPU. Running all three NIMs (Topic Control, Jailbreak Detection, Content Safety) simultaneously requires 3 GPUs.
If you have limited GPU resources (for example, 2 GPUs in your cluster), you can:
- Deploy only the NIMs you need for your use case (for example, Topic Control + Content Safety)
- Remove unused middleware layers from your IngressRoute
- Scale NIMs based on your security requirements and available GPU capacity
For production deployments with high traffic, consider separate GPU node pools for each NIM to ensure isolation and performance.
Step 4: Testing and Validation
Test your multi-layer security pipeline with real requests to verify proper functionality:
Blocked Request Example (Topic Control)
Request:
curl -X POST "http://ai-secure.example.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "Please help me set up Gopher Gateway with rate limiting features."
}
]
}'
Response:
HTTP/1.1 403 Forbidden
Content-Type: text/plain; charset=utf-8
Forbidden
Analysis: Request blocked by Topic Control layer because "Gopher Gateway" is identified as a competitor product.
Allowed Request Example (Passes All Layers)
Request:
curl -X POST "http://ai-secure.example.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "How do I configure Traefik middlewares for rate limiting in Kubernetes?"
}
]
}'
Response:
HTTP/1.1 200 OK
Content-Type: application/json
{
"id": "chatcmpl-...",
"object": "chat.completion",
"created": 1757671447,
"model": "gpt-4o",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "To configure Traefik middlewares for rate limiting in Kubernetes..."
}
}
]
}
Analysis: Request successfully passes through all security layers:
- Topic Control: "Traefik" is an allowed topic
- Content Safety: Request contains no harmful content
- Chat Completion: Forwards to OpenAI and returns AI response
Performance Considerations
GPU Resource Planning
Each NIM requires dedicated GPU resources:
- Topic Control NIM: ~8GB GPU memory
- Content Safety NIM: ~12GB GPU memory
- Jailbreak Detection NIM: ~4GB GPU memory
Plan your cluster capacity accordingly and consider:
- Node affinity to co-locate NIMs on the same GPU nodes
- Resource limits to prevent resource contention
- Horizontal scaling for high-traffic scenarios
Latency Optimization
NIMs add processing latency to each request:
- Topic Control: ~50-100ms per request
- Content Safety: ~100-200ms per request
- Jailbreak Detection: ~30-50ms per request
Optimize performance by:
- Deploying NIMs close to Traefik Hub (same cluster/region)
- Implementing selective filtering based on request characteristics
Troubleshooting
| Issue | Symptoms | Solution |
|---|---|---|
| ImagePullBackOff (401 Unauthorized) | Error: Failed to pull image: 401 Unauthorized | • Verify NGC API key is correctly base64 encoded • Use kubectl create secret --from-literal instead of environment variable substitution• Check NGC account permissions for specific NIM |
| ImagePullBackOff (402 Payment Required) | Error: Failed to pull image: 402 Payment Required | • Verify NGC account has access to the specific NIM • Check subscription status for commercial NIMs |
| Permission Denied on Cache Directory | PermissionError: [Errno 13] Permission denied: '/opt/nim/.cache' | • Add pod-level securityContext with runAsUser: 1000, runAsGroup: 1000, fsGroup: 1000• Ensure PVC has correct permissions |
| CUDA Runtime Error | RuntimeError: Failed to dlopen libcuda.so.1 | • Add securityContext: privileged: true to container• Set NVIDIA_VISIBLE_DEVICES: "all" and NVIDIA_DRIVER_CAPABILITIES: "compute,utility"• Mount NVIDIA drivers with hostPath volume if needed |
| Out of Memory (MIG Enabled) | Cuda Runtime (out of memory) with MIG partitions | • Disable MIG on GPU nodes (NIMs are incompatible with MIG) • Use NIM_MODEL_PROFILE to force vLLM backend• Reduce NIM_GPU_MEMORY_UTILIZATION to 0.7 or lower |
| Model Not Found (404 Error) | The model 'model-name' does not exist | • Use correct model names: llama-3.1-nemoguard-8b-topic-control, llama-3.1-nemoguard-8b-content-safety• Check NIM /v1/models endpoint for available models |
| High Latency | Requests taking >5 seconds | • Check network connectivity between components • Verify GPU utilization and memory usage • Consider request batching or caching strategies |
| Unexpected Blocking/Allowing | Security layers not working as expected | • Test NIMs directly to isolate middleware issues • Verify system prompts match working configurations • Check blockCondition and traceCondition expressions• Ensure model responses match expected format |
This integration provides enterprise-grade content security for AI applications while maintaining the flexibility and performance required for production deployments. The combination of NVIDIA's specialized NIMs with Traefik Hub's AI Gateway creates a powerful platform for safe, controlled AI interactions.
